由 王豪迈 发布于2025-03-20
在 GTC 2025 Keynote,NVIDIA CEO 黄仁勋强调 LLM 计算正在从侧重预训练 (pre-train) 转向以推理(inference)为中心的发展阶段。AI 推理在大规模应用中已经成为一种爆发的计算需求,所需算力和内存带宽不亚于训练所需。随着越来越多的大模型投入使用,业界关注的重点正转向推理算力建设。而 AI Factory 将取代传统数据中心,企业需要面向推理优化的全栈方案。为此,NVIDIA 发布了全新的 NVIDIA Dynamo 【1】推理引擎,作为大规模推理的“AI 操作系统”。
推理过程中对历史对话上下文、知识库等进行高效利用是关键。因此,如何存储和快速读取 KVCache 推理中间结果,避免重复计算,成为提升推理性能的关键所在。NVIDIA 在大会上发布的端到端推理优化方案涵盖了模型执行调度、KVCache 管理和高速存储IO等多个层面,旨在降低推理成本达到 35 倍之巨,以应对推理阶段爆炸式增长的算力需求。
KVCache 指的是模型在自注意力计算中生成并存储的中间结果(键值矩阵),通过复用这些中间结果,模型可以大幅减少重复计算,加快推理速度,降低延迟。
总之,GTC 2025 的信号很明确:AI 推理已成为新一轮算力竞赛的主战场,从硬件架构到软件平台均围绕推理进行重塑和优化。
推理操作系统:NVIDIA Dynamo
NVIDIA Dynamo 是本届 GTC 发布的开源分布式推理框架,被誉为大规模推理的“AI 引擎栈”。它继承了 Triton 推理服务器的经验,并在其上引入全新的模块化架构,以实现对分布式推理的优化支持。Dynamo 主要由四大核心组件组成:
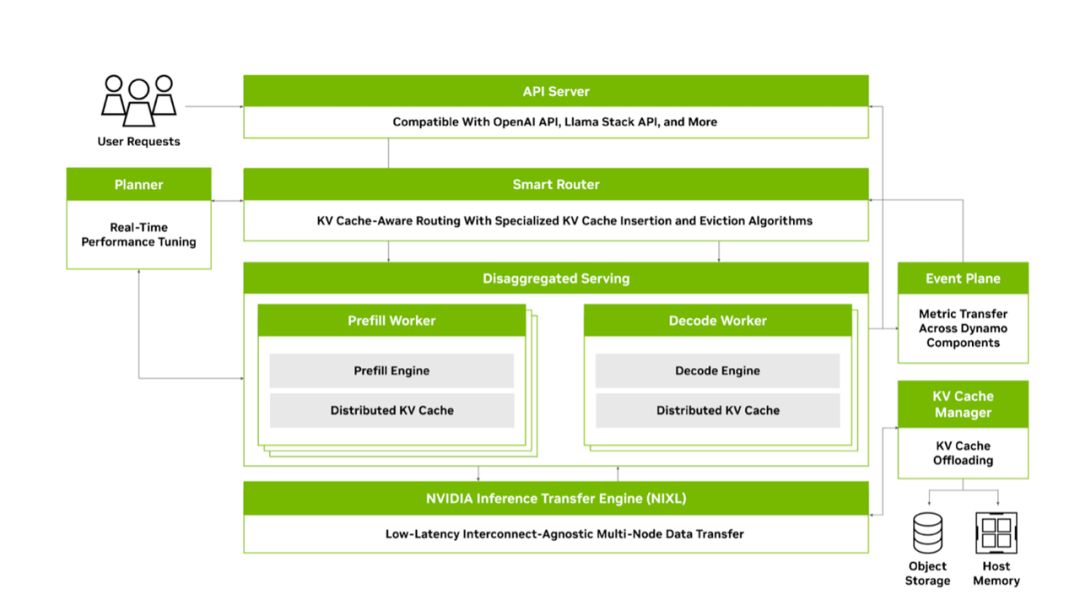
GPU Planner
负责根据负载动态调整集群中用于预填充(prefill)和解码(decode)的 GPU 资源比例,自动伸缩并分配 GPU,以适应吞吐和延迟 SLO 需求。
Smart Router
解决多 GPU 集群中 KVCache 重用与请求调度问题。LLM 在响应每个请求前都要计算输入的 KVCache,这个计算随输入长度平方级增长,非常耗费算力。Smart Router 通过对每个新请求计算“重叠得分”,判断其与集群中现有哪块 KVCache 相似。它使用 Radix Tree 索引追踪了整个集群中已缓存的 KV 片段位置,并设计了专门的插入/淘汰算法确保最有价值的缓存留在高速层。
Distributed KV Cache Manager
提供对 KVCache 的分层存储和弹性扩展的支持。随着应用规模增长,同一时间需要保留的 KVCache 总量远超单卡 GPU HBM 容量,因此将 KVCache 从 GPU HBM 主动移出,存放到更低成本的存储层级,如 CPU DRAM、本地 SSD,高性能共享存储。
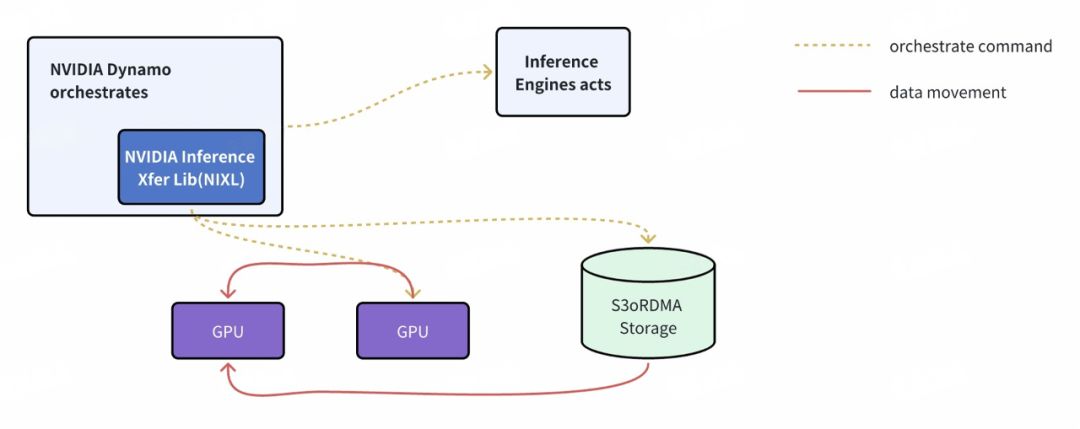
NVIDIA Inference Transfer Library(NIXL)
高吞吐、低延迟的点对点数据传输库,负责在不同设备/节点/存储之间快速移动推理数据。它提供统一的 API 抽象,无需关注底层是通过 NVLink、PCIe、InfiniBand 还是以太网进行传输,也不必区分目标是在 GPU HBM、CPU DRAM、SSD 还是远端存储。NIXL 针对推理场景做了优化,支持非阻塞、非连续内存的数据搬移,并能够选择最优传输路径。在分离式推理中,NIXL 的核心任务是实现 Prefill 阶段输出的 KVCache 从预填 GPU 到解码 GPU 的低延迟传输。其中采用了 GPU-Direct Async (IBGDA)【2】 机制,使得 GPU 到 NIC 的控制流和数据流都无需经过 CPU 代理。同时,NIXL 也对接了 NVIDIA GPUDirect Storage (GDS)、UCX【3】 等多种后端。
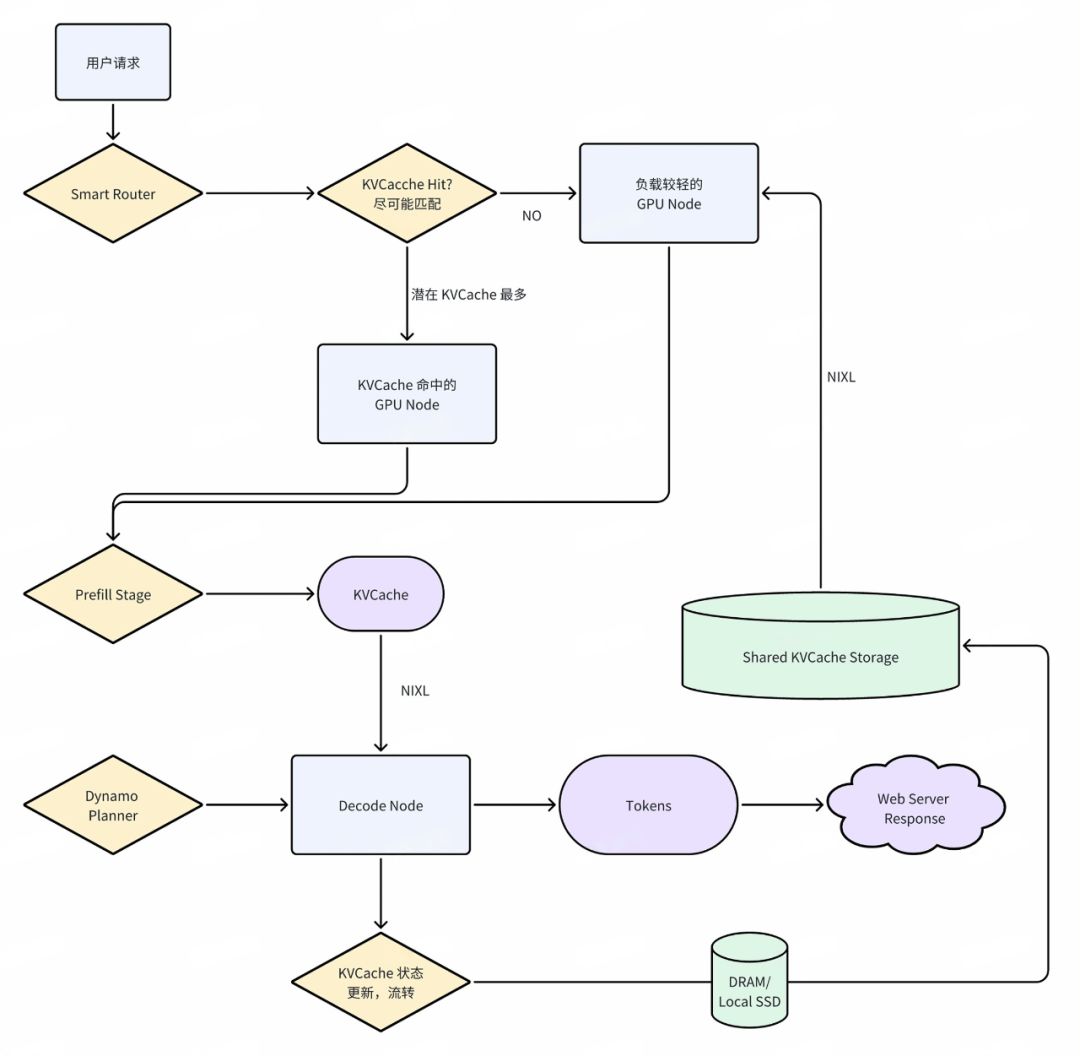
通过以上步骤示例可以看到,Dynamo 围绕 KVCache 的产生、传输、存储与复用建立了一套完善机制,从路由避免重复计算,到多级存储降低成本,再到高速链路缩短延迟,形成了端到端的推理优化方案。这使得部署 Dynamo 的推理服务能够在保证低延迟的同时,大幅提高 GPU 利用率和吞吐量。
Mooncake:分布式 KVCache 的先导实践
Mooncake 【4】是国内 Kimi 在 2024 年公开的 LLM KVCache 架构方案,Mooncake 最早在 24 年 7 月发表在 Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving【5】,其特色在于 KVCache-centric 的设计理念。NVIDIA Dynamo 在其项目文档中多次致敬 Mooncake 的设计,从 Dynamo 项目的代码提交记录来看,应该也是迟于 Mooncake 的公开发表。
总体上,Mooncake 与 NVIDIA Dynamo 有不少异曲同工之处,都采用 Prefill-Decode 分离架构,并且充分利用多级存储资源来扩展 KVCache 容量,抛开架构上的大同小异,二者在实现细节和技术侧重点上也存在差异:
数据流动与通信优化
在数据传输方面,Mooncake 和 Dynamo 都非常强调借助 RDMA 等手段实现 GPU 间的高效通信。Mooncake 的 Transfer Engine 是其自研的高性能数据传输库,支持 TCP、RDMA (包括 NVIDIA GPUDirect) 以及 NVMe-oF 协议,通过多路径聚合和拓扑感知优化达到极致带宽利用。测试显示,使用 8×400Gbps RoCE 网络时,Mooncake Transfer Engine 可以实现高达 190GB/s 的吞吐。这个引擎被用于 Mooncake Messenger 服务来进行 KVCache 跨节点传输,以及用于 P2P Store 在节点间共享检查点等大文件。NVIDIA Dynamo 则通过 NIXL 抽象出了类似的加速通信,通过背靠 NVIDIA 对 IB、NVLink 等网络技术的优势,直接支持更多元的存储类型和网络。
Mooncake 与 vLLM 的整合
vLLM 【6】是近年兴起的高性能开源 LLM 推理引擎,因其独特的分页注意力(PagedAttention)技术实现了对 KVCache 的高效管理和批处理,被广泛采用。Mooncake 项目很早就与 vLLM 进行对接,目标是将 Mooncake 的 RDMA 加速和分布式 KV 存储能力赋予 vLLM 的推理架构。Mooncake 项目已经在 2025 年 3 月开源了 Mooncake Store 并宣布 vLLM 的 xPyD 分离式预填解码将基于 Mooncake Store 提供支持。未来 Mooncake 将进一步整合 vLLM 支持 KVCache 的 Zero Copy 能力,以及支持全局 KVCache 利用。在 PD 分离上,未来也将实现更灵活的动态 Prefill/Decode 角色转换(根据负载情况自动调整),支持 Chunked Prefill 机制以优化长上下文请求处理效率。
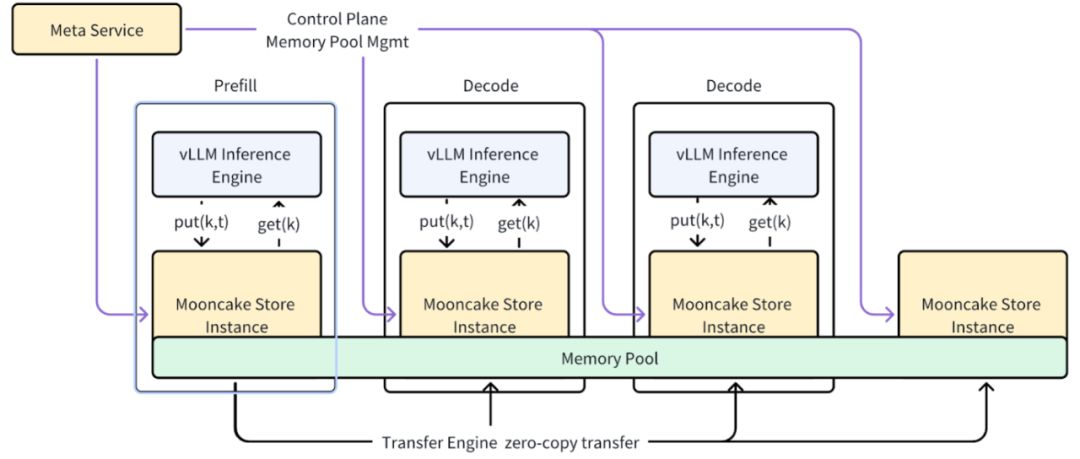
其实不仅是 Mooncake,DeepSeek 在 R1 模型发布后的一系列技术报告中都支持了 PD 分离,KVCache 大规模化的推理系统建设。
助力 KVCache 无限扩展:S3 over RDMA
在 GTC 25 的存储相关话题上,GPU Direct Storage 的生态也出现了重要扩展。其中焦点之一是通过 RDMA 访问对象存储的 S3 协议。NVIDIA 存储架构师 CJ Newburn 在会议分享中详细介绍了这一技术如何融入 GPU Direct Storage 生态,成为 AI 基础设施的关键环节。

目前已经有多家存储系统供应商展示了各自对 GPUDirect S3 的支持,将其作为 AI 数据方案的重要卖点。并通过支持 GPUDirect,对接 NVIDIA BlueField 架构,用于大模型训练和推理。以下是 NVIDIA 给出一个 S3 TCP 和 S3 over RDMA 的对比:
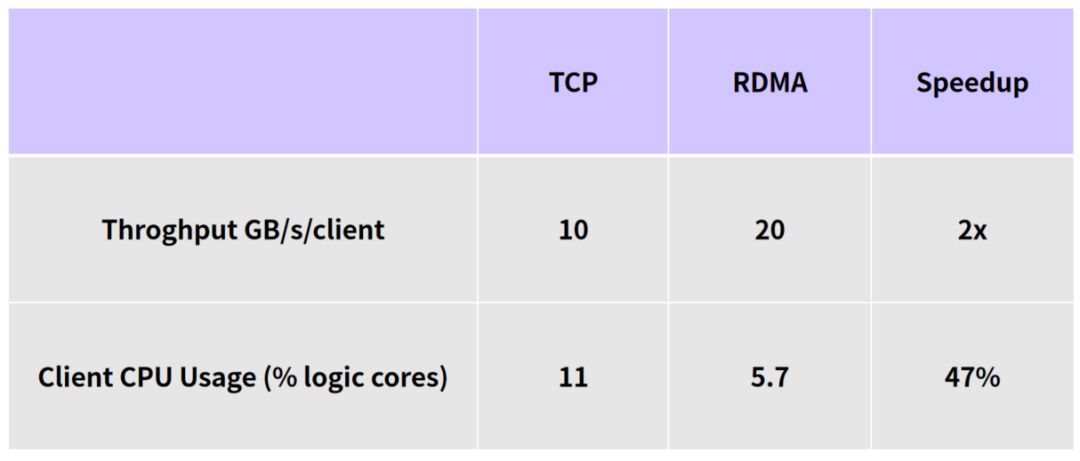
NVIDIA Dynamo 也将受益于 S3 over RDMA 技术,其 NIXL 库底层已经实现了 GDS 支持,并将尽快支持 cuObject(即 CUDA 的 S3 over RDMA 客户端)。这意味着,在 Dynamo 部署中,KVCache Manager 可以把冷缓存写入支持 RDMA 的 S3 存储,再通过 NIXL 高速读回,整个过程对于 Dynamo 应用层来说是透明的。
总结与趋势
GTC 2025 释放的明确信号是:AI 推理已取代训练成为算力建设的重中之重。这种转变源自大模型从研发阶段走向大规模部署应用,推理所面对的是真正海量的用户请求和上下文数据处理需求。NVIDIA 将这一阶段称为“推理计算时代”,并用实质行动展示了针对推理全方位优化的技术栈。无论是 Blackwell GPU 架构为推理做出的特殊强化,还是 Dynamo 框架在软件层面引入的系列创新,本质上都是为了应对“推理 token 爆炸”所需的计算与数据流动挑战。
展望未来,我们预计对象存储将在 AI 推理领域扮演越来越重要的角色。对象存储天生具备巨大的扩展性和较低的成本,对于需要保存海量对话上下文、知识缓存的场景非常契合。而通过 S3 over RDMA 等创新,对象存储的性能短板也被补齐,摇身一变成为“高速外部内存”。
从 DeepSeek 开源成果 到 Mooncake 与 vLLM 的深度整合,再到 NVIDIA Dynamo 对 Mooncake 设计理念的公开致谢,GTC 2025 的舞台传递出一个信号:中国 AI Infra 的开源力量已从“跟随”走向“引领”。在推理时代的技术浪潮中,国内团队凭借对 KVCache、分布式存储等核心领域的超前探索,正为全球 AI 基础设施的演进注入不可忽视的创新动能。中国 AI Infra 的主动布局不仅是对技术趋势的敏锐响应,更是对开源协作精神的深度践行。
XSKY 作为国内领先的分布式存储系统提供商,在国内对象存储软件市场多年处于领先地位,我们正在积极拥抱新的推理开源生态,推动对象存储与 AI 算力的深度融合,将很快推出面向大规模推理服务的高性能数据池服务,并结合企业数据湖建设经验,为 AI 数据提供全生命周期管理。
XSKY 正密切关注 AI 大规模推理系统的建设,正在协同上下游领先的合作伙伴,为 AI 存储提供前沿解决方案,欢迎联系 XSKY 销售代表!

注:
【1】NVIDIA Dynamo
https://github.com/ai-dynamo/dynamo/
【2】GPU-Direct Async (IBGDA)
【3】UCX
https://github.com/openucx/ucx
【4】Mooncake
https://github.com/kvcache-ai/Mooncake
【5】Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving
https://arxiv.org/abs/2407.00079
【6】vLLM
https://docs.vllm.ai/en/latest/
















