
























挑战
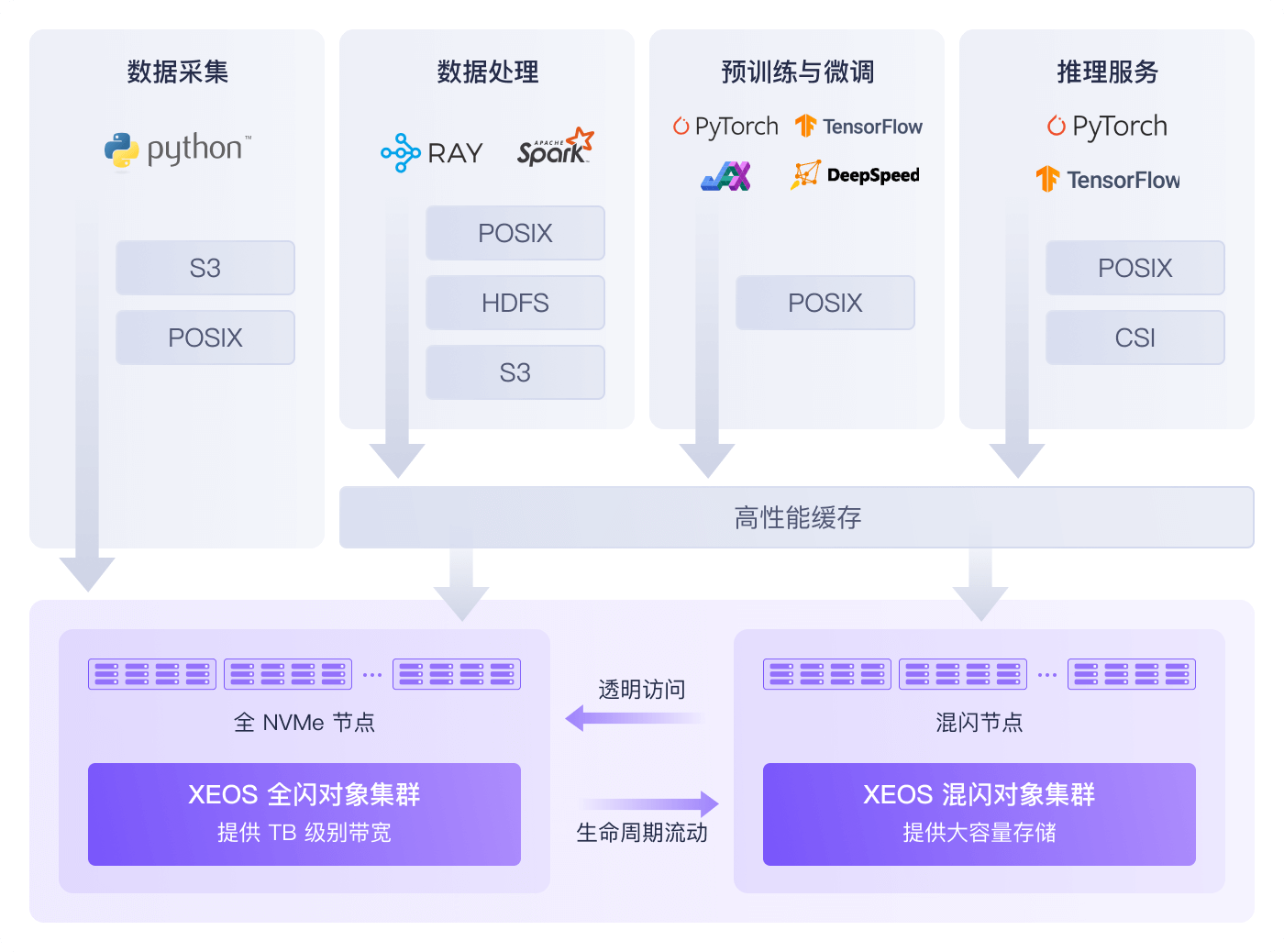
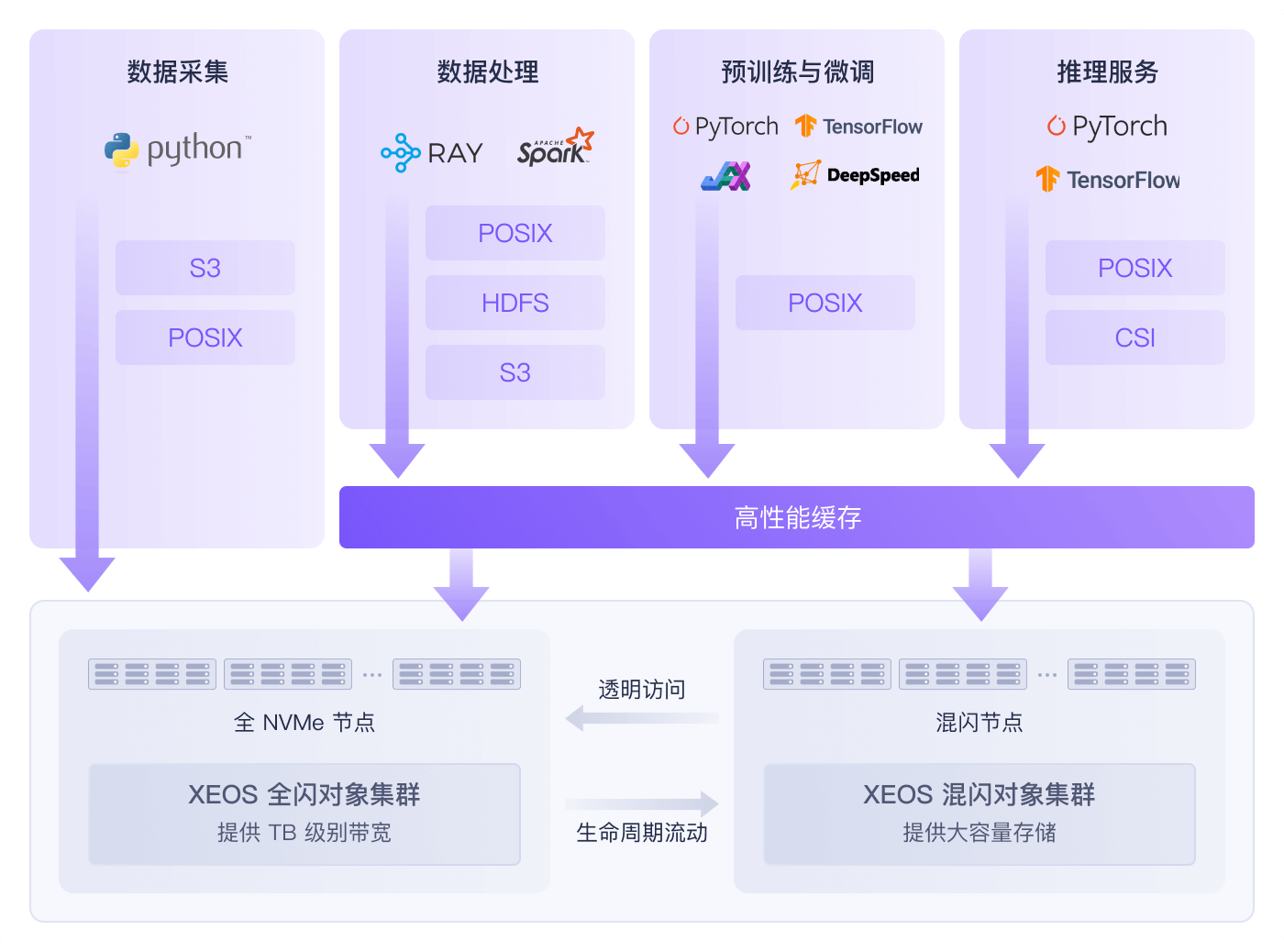
在进行万亿参数模型训练时,频繁的 Checkpoint 写入耗时过长(超过 30 分钟),导致训练中断恢复成本高昂,且海量训练语料(数亿小文件)的读取效率低下,GPU 平均利用率不足 50%。

收益
采用本方案后,Checkpoint 写入时间缩短至 3 分钟内,GPU 平均利用率提升至 90%以上,整体模型训练周期缩短了 40%。

挑战
国家级大模型实验室,多个实验组数据散落于不同 NFS,管理混乱。当集群扩展至数百 GPU 时,传统 NFS 在处理海量小文件和 TB 级模型断点时性能严重不足,导致 GPU 算力闲置。
收益
采用本方案后,所有科研数据统一到对象存储数据湖。高性能 POSIX 接口将数据集加载速度提升 10 倍,TB 级断点保存从"小时级"缩至"分钟级",极大加速了大模型的研发迭代进程。

挑战
作为公共算力服务平台,需要同时为众多不同类型的租户提供服务,租户应用和数据类型多样,对存储的性能、成本和安全性要求各不相同。
收益
部署本方案后,以统一的对象存储作为后端,通过逻辑隔离和缓存策略,为不同租户提供了兼具高性能和经济性的"按需分配"的数据存储服务。简化了运维管理,提升了平台的整体服务能力和商业竞争力。


