由 XSKY星辰天合 发布于2026-07-02
随着大模型推理需求爆发式增长,KV Cache 存储已成为 AI 基础设施的核心瓶颈之一。为系统评估 KV Cache 专用存储方案的技术成熟度与场景适配能力,开放数据中心委员会(ODCC)AI 存储实验室联合 XSKY 星辰天合,基于NVIDIA 计算与网络平台、大普微 SSD 硬件,完成了面向多形态部署、多模型架构、多存储策略的 KV Cache 存储系统全面评测。本次测试以 XSKY 星飞推理存储系统 MeshFusion 为评测对象,验证其在推理场景下的性能表现与规模化落地能力。
作为 AI 基础设施创新公司,XSKY 星辰天合致力于打造高性能、可扩展的全链路 AI 数据底座,自研 MeshFusion 星飞推理存储系统直击 KV Cache 痛点。本次 ODCC 评测充分验证了其架构创新与生态适配能力,可为智算及大模型企业提供高性价比的推理存储解决方案。
测试方案:多种部署形态,覆盖多元场景
XSKY 星飞推理存储系统 MeshFusion 是专为推理场景设计的存储扩展系统,围绕 KV Cache 的数据特征进行深度自研,兼顾 G3 本地盘共享能力与 G4 高速访问性能,并兼容主流算力生态。系统采用极简基础架构设计,融合智能网络引擎,原生支持 KV Cache 接口,具备良好的可扩展性与适配性。
在部署方式上,MeshFusion 支持多种灵活形态:
直接嵌入现有 GPU/NPU 服务器:系统可复用服务器自带的闲置 NVMe 盘,通过高速 RDMA 组建集群级共享 KV Cache 存储池,打破本地 SSD 的孤岛限制。该方式无需额外采购独立存储服务器,改造投入低,适用于已有算力集群的轻量化升级。
部署于 DPU 速卡:在此模式下,KV Cache 数据流绕过主机 CPU 与内存,经由 DPU 直达 GPU 显存,实现 CMX 近存计算架构。配合 JBOF 全闪硬件构建大容量高速共享存储池,并依托 Spectrum-X 高速网络,可满足推理任务对高带宽、低延迟的严苛要求,尤其适合中大型规模化推理 Token 工厂的部署需求。
独立集群部署:基于该系统可独立构建专用的存储集群,能够高效承载海量训练数据集与推理过程中的 KV Cache,为企业 AI 基础设施提供高性能、可扩展的统一存储底座。
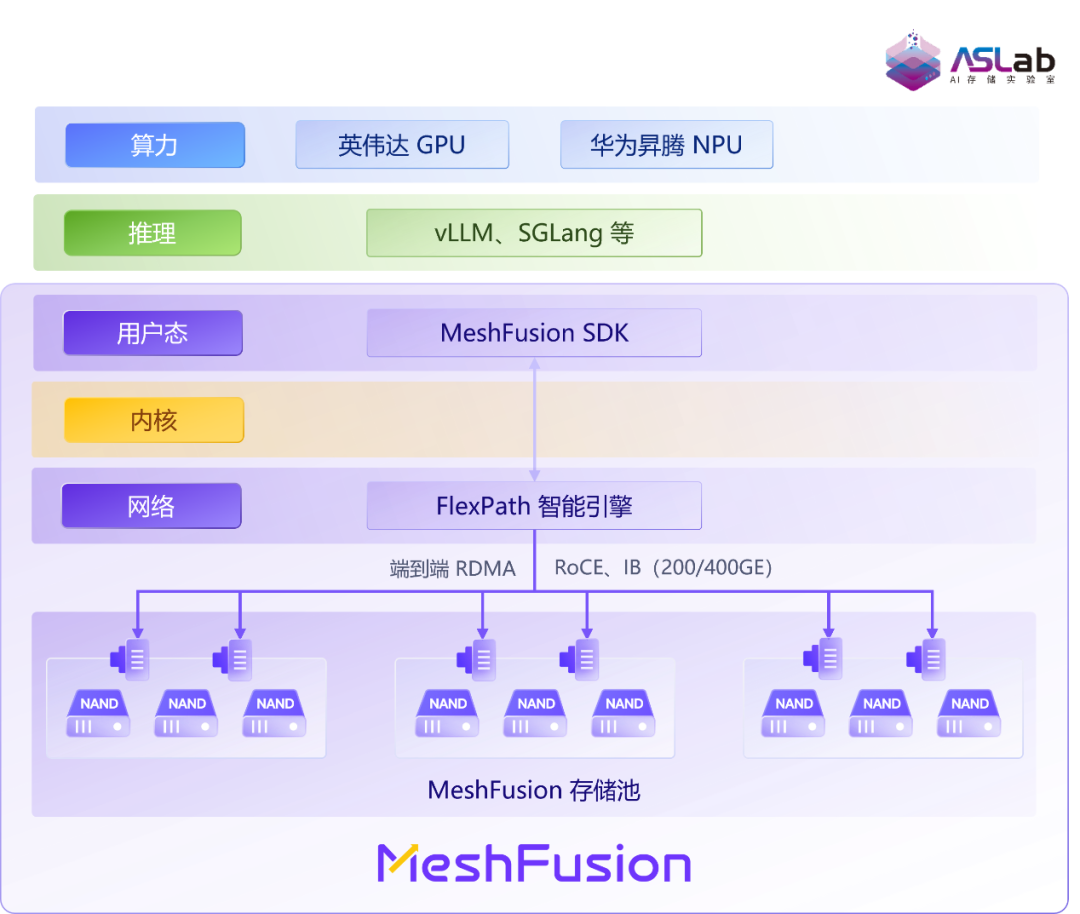 图1 MeshFusion架构图
图1 MeshFusion架构图
测试环境:一套环境,验证多种方案
总体概述
本次测试聚焦于验证推理过程中 Prefill 阶段及 Prefill-Decode 混合阶段的性能表现,覆盖 DeepSeek-R1、Qwen3-235B、DeepSeek V4 与 GLM-5.1 等主流大模型。在推理架构层面,测试同时纳入了 PD 一体与 PD 分离两种主流方案,以评估不同调度策略下的效率差异。硬件配置上,测试选用高端 HBM GPU 服务器与中端 GDDR GPU 服务器两类算力节点,以兼顾高吞吐与高性价比的部署需求;存储系统除采用传统 X86 存储服务器外,还引入了基于 NVIDIA BlueField-3 DPU 的 JBOF 全闪硬件,着力探索类似 NVIDIA CMX 的前沿近存计算架构。上述多维度的组合设计,有效覆盖了业界当前主流以及未来演进中的各类硬件部署形态,为推理存储系统的实际选型提供了坚实的数据支撑。
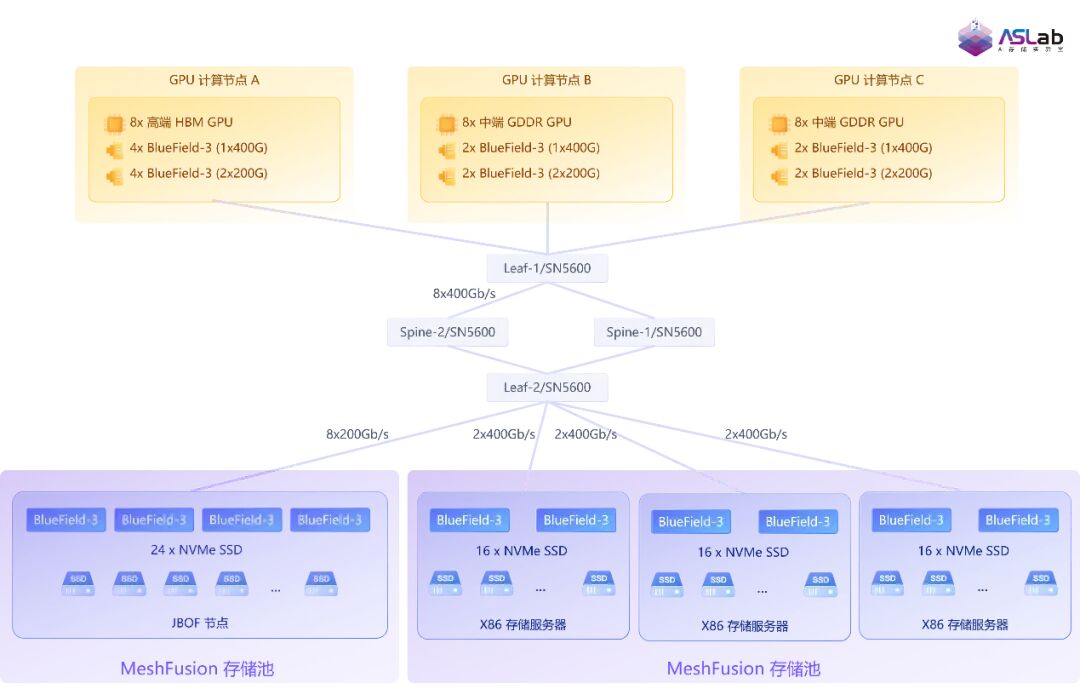 图2 测试环境网络拓扑架构图
图2 测试环境网络拓扑架构图
方案介绍
本次测试具有四种方案组合,具体如下表所示。
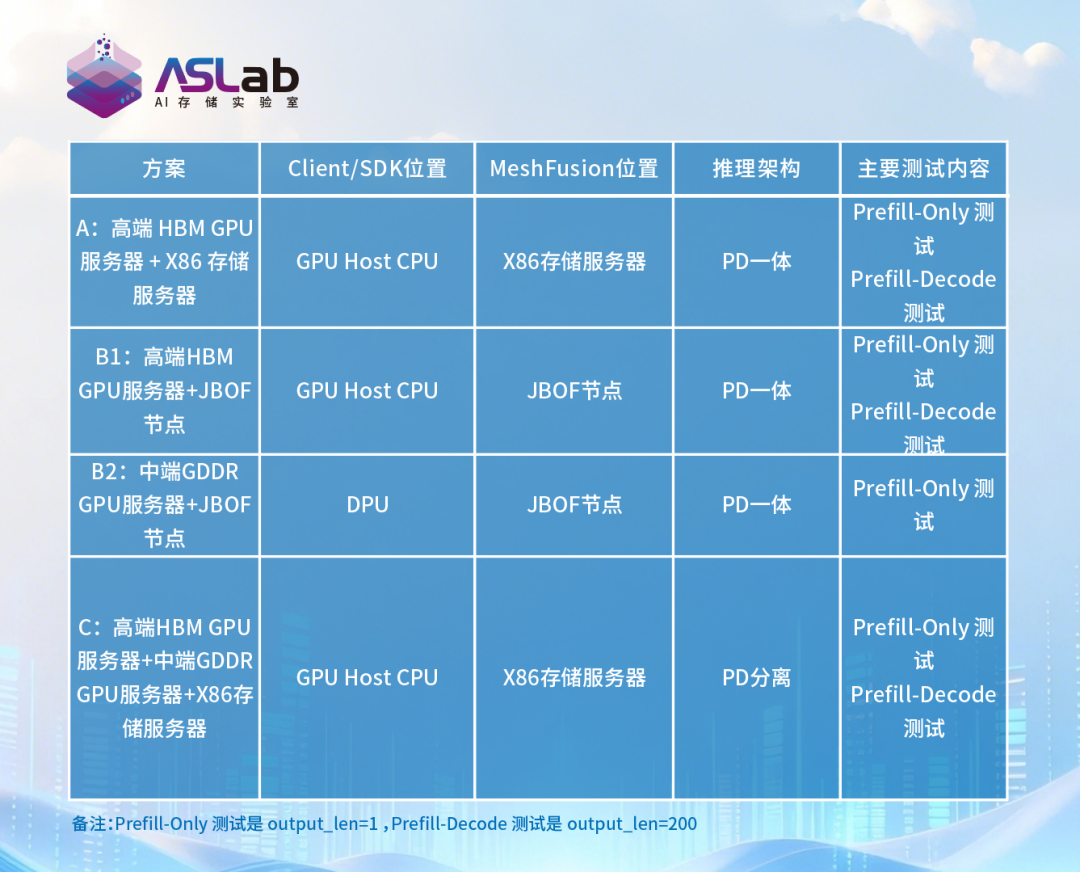
A:高端 HBM GPU 服务器 + X86 存储服务器
验证 MeshFusion 在“独立集群部署”下的 KV Cache 卸载性能。
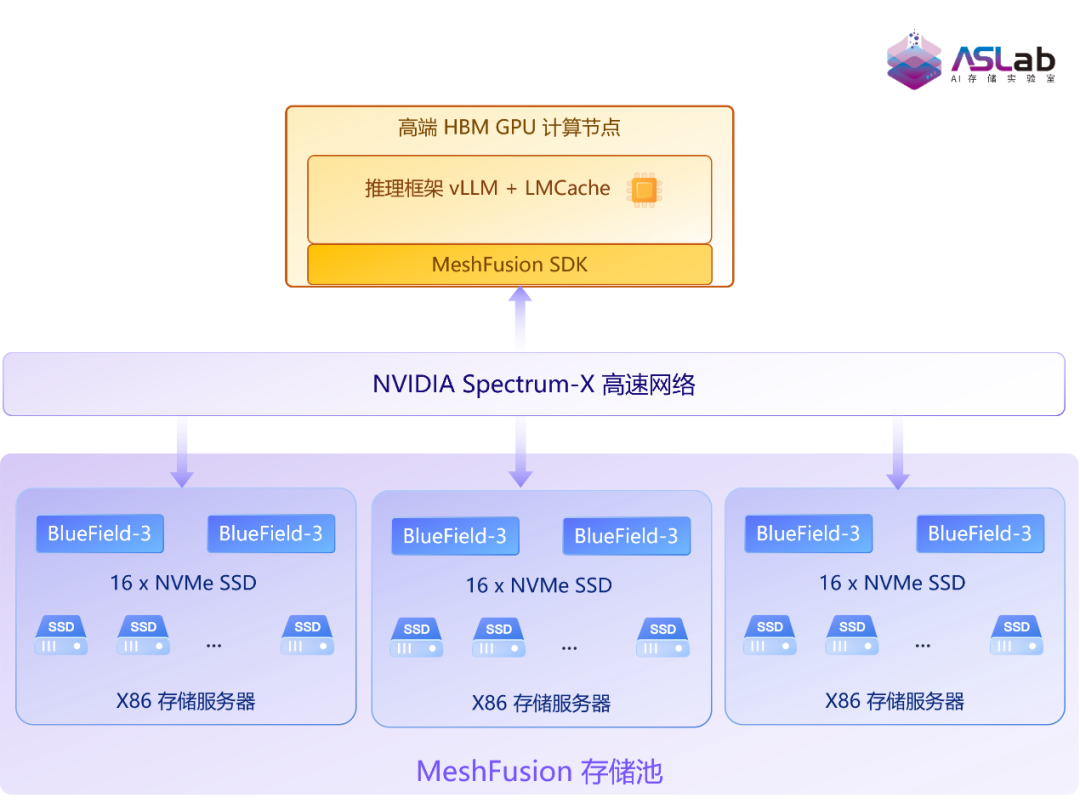 图3 方案A拓扑架构图
图3 方案A拓扑架构图
B1:高端 HBM GPU 服务器+JBOF 节点
验证 MeshFusion 在“BlueField-3 DPU+JBOF 部署(NVIDIA CMX 架构)”下的 KV Cache 卸载性能。
 图4 方案B1拓扑架构图
图4 方案B1拓扑架构图
B2:中端 GDDR GPU 服务器+JBOF 节点
验证 MeshFusion 在使用“NVIDIA GDR(GPUDirect RDMA)”下的 KV Cache 卸载性能。
 图5 方案B2拓扑架构图
图5 方案B2拓扑架构图
C:高端 HBM GPU 服务器+中端 GDDR GPU 服务器+X86 存储服务器
验证 MeshFusion 在“PD 分离场景”下的 KV Cache 卸载性能。其中 P 节点和 D 节点之间的 KV Cache 传输使用 NixlConnector,KV Cache 卸载使用 MeshFusion SDK。
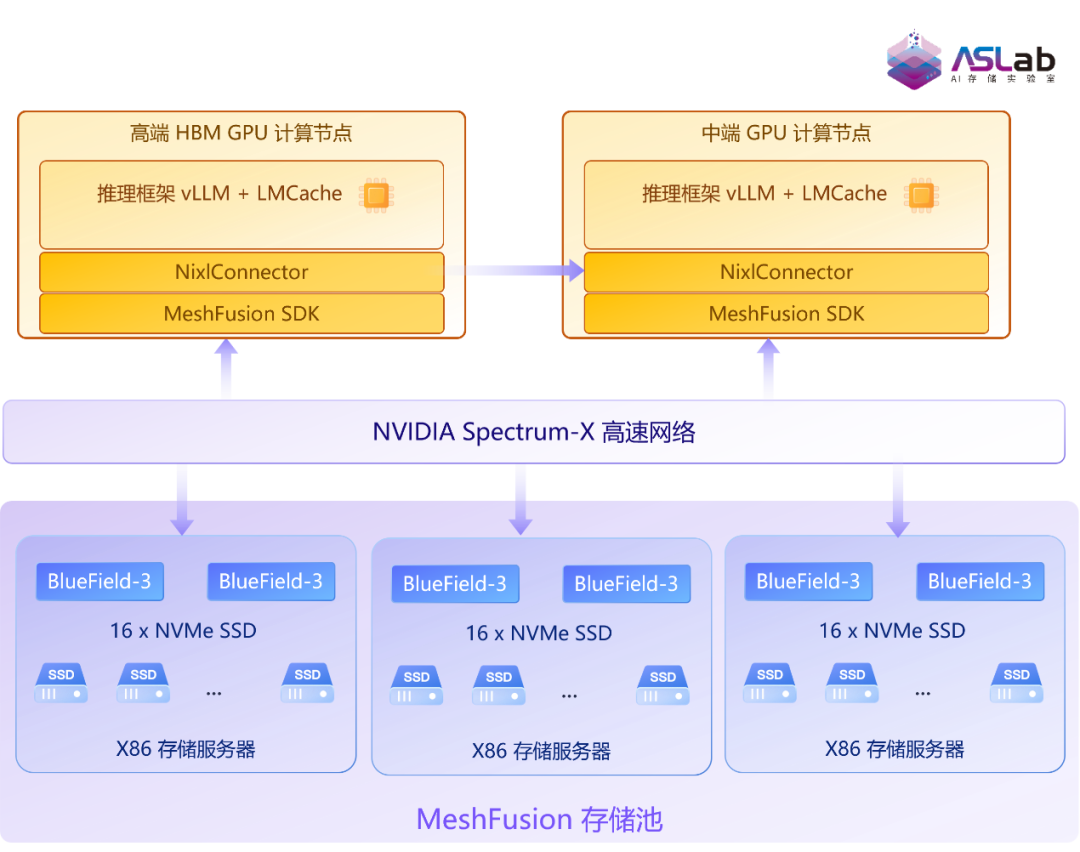 图6 方案C拓扑架构图
图6 方案C拓扑架构图
核心成果:创新架构,国内领先
国内首个实现类似 NVIDIA CMX 架构的 KV Cache 存储方案
基于 XSKY MeshFusion 的轻量化架构,将其部署于 BlueField 3 DPU 中,实现了 KV Cache 数据与 GPU 显存的直通,架构如图 7 所示。
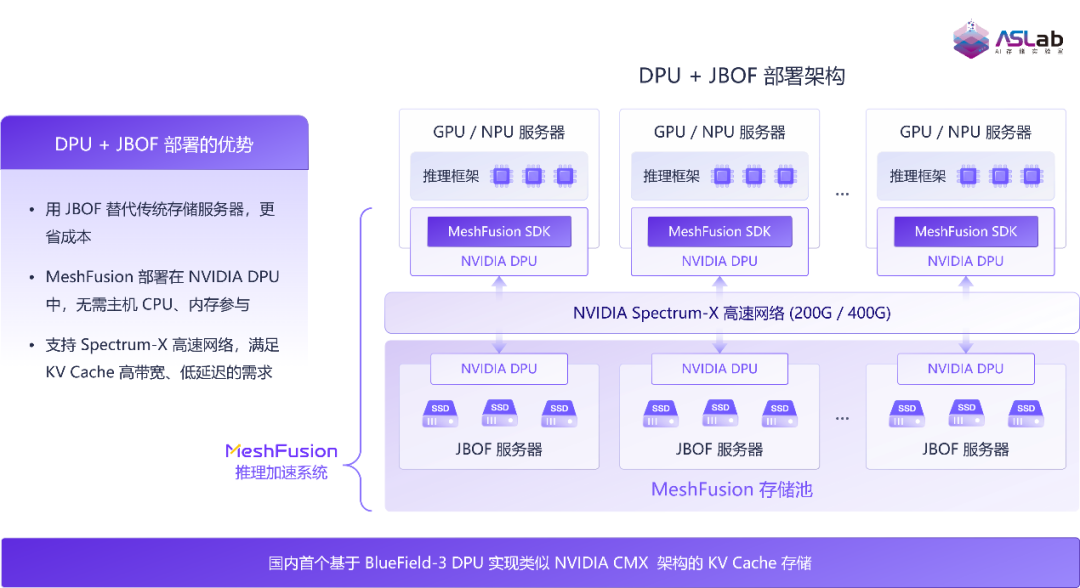 图7 DPU+JBOF部署架构图
图7 DPU+JBOF部署架构图
在此架构上,本次测试以方案 B1 为基础,针对 JBOF 存储后端开展了 Prefill-only 场景的测试,重点对比 KV Cache 命中(Warm)与重算(Cold)的性能差异。结果表明,卸载 KV Cache 带来的收益极为显著:TTFT 从数十秒锐降至命中后的百毫秒甚至数秒,尤其在长序列场景中降幅最大;而吞吐量(TPS)则整体提升了一个数量级(达 10 至 28 倍),在 Cache 命中时普遍稳定在 7 万至 10 万 Tokens/s。上述数据充分证明,基于 DPU+JBOF 构建的、形态类似 NVIDIA CMX 的存储架构,能够高效承载 KV Cache 卸载,为企业 AI 推理提供坚实的性能支撑,测试数据详见图 8。
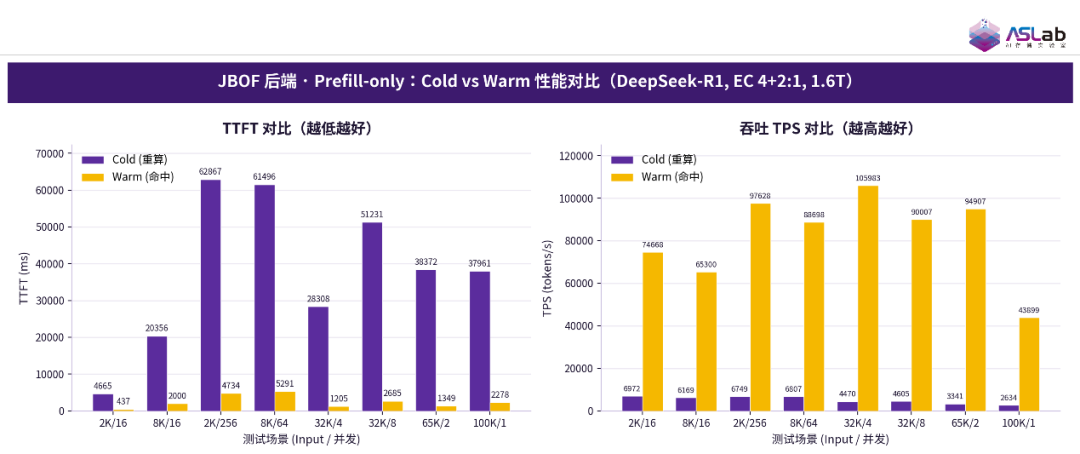 图8 JBOF后端·Prefill-only: Cold vs Warm性能对比(DeepSeek-R1,EC 4+2:1,1.6T)
图8 JBOF后端·Prefill-only: Cold vs Warm性能对比(DeepSeek-R1,EC 4+2:1,1.6T)
为验证基于 DPU 的 JBOF 后端能否等效替代 X86 存储后端,AI 存储实验室在相同条件下对方案 A(X86)与方案 B1(JBOF)进行了 Prefill-only 以及 Prefill-Decode 一体对比测试,结果分别如图 9 和图 10 所示。
在 Prefill-only 测试中,两者的 TTFT 加速比与 TPS 加速比高度接近,在 KV Cache 卸载负载下性能表现基本持平,由此充分证明基于 DPU 的 JBOF 后端完全可作为 X86 存储的可靠替代方案,为实际部署提供了更具灵活性的硬件选择。
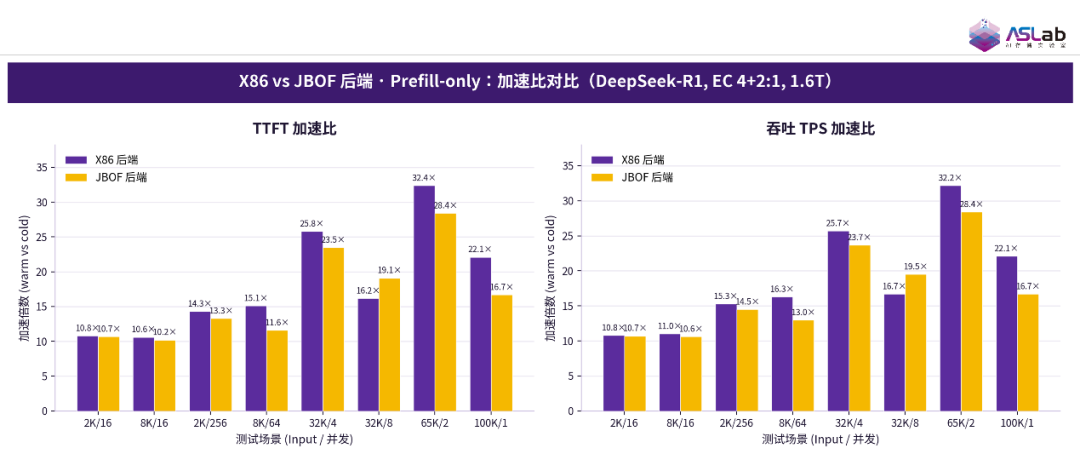 图9 X86 vs JBOF后端·Prefill-only: 加速比对比(DeepSeek-R1,EC 4+2:1,1.6T)
图9 X86 vs JBOF后端·Prefill-only: 加速比对比(DeepSeek-R1,EC 4+2:1,1.6T)
在 Prefill-Decode 一体测试中,以每秒完成请求数(req/s)衡量端到端吞吐,X86 存储后端与 JBOF 后端的加速比依然相似。这进一步说明 JBOF 后端在真实推理负载(含 Decode 阶段)下同样可用。
 图10 X86 vs JBOF后端·Prefill-Decode: req/s加速比对比(DeepSeek-R1,EC 4+2:1,1.6T)
图10 X86 vs JBOF后端·Prefill-Decode: req/s加速比对比(DeepSeek-R1,EC 4+2:1,1.6T)
在方案 B2 的基础上,本次进一步开展了 GPUDirect RDMA(GDR)技术的 KV Cache 卸载测试(Prefill‑Only 场景)。通过在 GPU 服务器部署 Qwen3‑235B 模型进行推理,并在 4 块 BlueField‑3 DPU 上安装 MeshFusion SDK,构建 GDR 直通链路。本次测试着重对比了 KV Cache 命中(Warm/Run2)与重算(Cold/Run1)的性能。结果表明,吞吐量(TPS)从重算时的约 800 tokens/s 跃升至命中后的 4 万 tokens/s 以上,如图 11 和图 12 所示。这一结果充分验证了 GDR 读写路径打通后,KV Cache 卸载在 GPUDirect 方案下能够带来数量级的性能收益,证明该技术路线在高效推理场景中的巨大潜力。
 图11 GDR方案·Prefill-only: Cold vs Warm性能对比(Qwen3-235B,RTX6000 DPU+JBOF,4GPU+4DPU)
图11 GDR方案·Prefill-only: Cold vs Warm性能对比(Qwen3-235B,RTX6000 DPU+JBOF,4GPU+4DPU)
 图12 GDR方案·Prefill-only:KV Cache卸载加速比(Qwen3-235B,长序列峰值58×)
图12 GDR方案·Prefill-only:KV Cache卸载加速比(Qwen3-235B,长序列峰值58×)
基于 BlueField-3 DPU 的 JBOF 的成功,可以证明 XSKY MeshFusion 具备平滑移植到 NVIDIA CMX 平台的能力,发挥出分布式 KV Cache 存储软件更大性能潜力。
基于 NVIDIA Spectrum-X 网络,存储与网络栈无明显软件瓶颈,扩展性可预测
本次测试基于 NVIDIA Spectrum-X 网络环境,结果表明,集群 EC 顺序读性能达 272.1 GiB/s,占三台存储节点网络物理极限的 97.4%;单客户端 EC 顺序读在 1.6T 条件下亦达到 167.0 GiB/s,为单机网络极限的 89.7%。两者均逼近各自的物理上限,充分证明存储软件栈能够高效压满 RDMA 网络,不存在明显的软件层瓶颈。此外,带宽容量可按网口数量线性规划,这一特性为大规模部署场景下的硬件选型与成本测算提供了可靠的量化依据。
 图13 EC 1M顺序读达成率:集群vs单客户端
图13 EC 1M顺序读达成率:集群vs单客户端
在此展示 3 台存储节点的 6 个 RDMA 网口(400G)的带宽监控,可以看到网口带宽达到 46 GiB/s,接近打满网卡物理带宽。
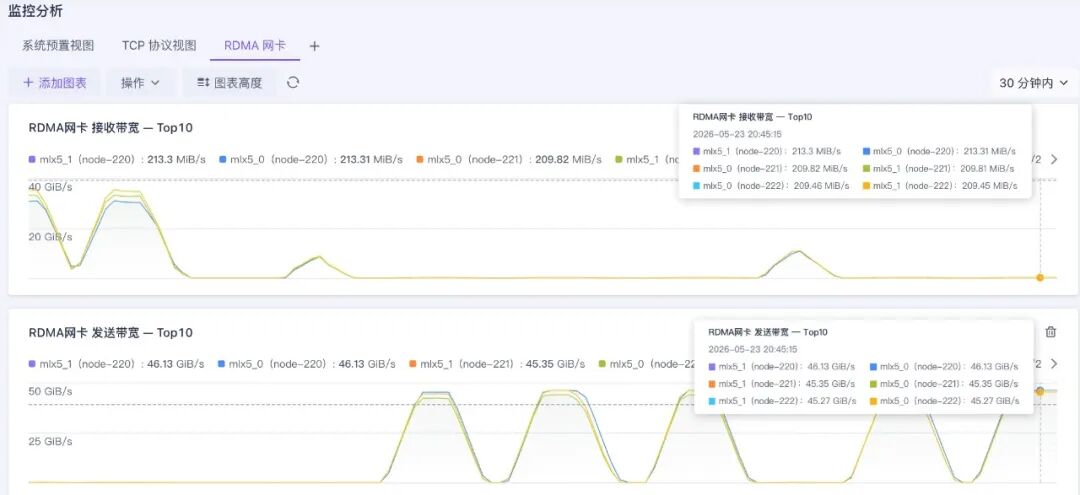 图14 带宽监控图(截选)
图14 带宽监控图(截选)
国内领先的支持混合注意力大模型的 KV Cache 存储方案
随着 DeepSeek-V4 、GLM-5.1 等采用混合注意力架构的模型兴起,其 KV Cache 结构与传统 MHA/GQA 显著不同。 本次测试结果表明,KV Cache 卸载后命中吞吐均远高于重算:V4-Flash 的命中吞吐稳定在 4 万–6 万 Tokens/s,吞吐加速比是 6.6 倍,GLM-5.1 更高、峰值超过 15 万 tokens/s,吞吐加速比是 57.4 倍。这证明存储侧能正确处理混合注意力模型的异构 KV 布局并保持高卸载收益。
 图15 混合注意力模型·Prefill-only: Cold vs Warm性能对比(X86,EC,1.6T)
图15 混合注意力模型·Prefill-only: Cold vs Warm性能对比(X86,EC,1.6T)
EC 纠删码和单副本在 KV Cache 卸载场景无性能差距
在方案 A 的 Prefill‑only 与 Prefill‑Decode 两类测试场景中,本次测试对比了“EC 4+2:1 纠删码”与“单副本”存储策略下的性能表现。结果表明,两者的 TTFT 加速比与 TPS 加速比均无明显差异,因此生产部署可直接采用 EC 纠删码策略,在不牺牲推理性能的前提下同时获得更高的存储容量利用效率与数据可靠性。
进一步地,在 EC 策略下,KV Cache 卸载带来的收益依然显著:命中(Warm)相比重算(Cold),TTFT 从数十秒降至百毫秒或数秒,长序列场景下降幅最大;吞吐(TPS)提升一个数量级(10 倍~32 倍),命中时普遍达到 7 万至 11 万 Tokens/s。该结果充分证明,即便在纠删码带来的额外计算与存储开销下,KV Cache 卸载的收益仍能得到完整保留,为实际生产环境中兼顾性能与可靠性的存储选型提供了有力支撑。
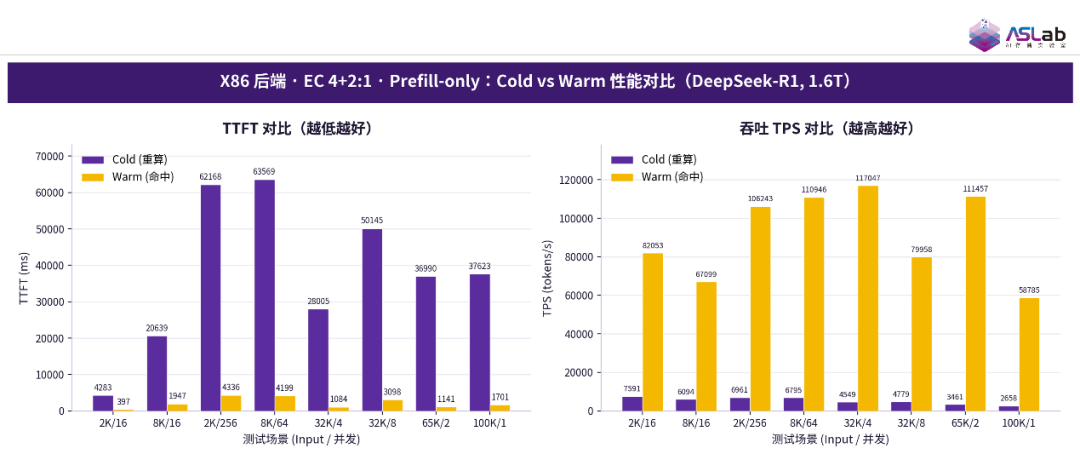 图16 X86后端·EC 4+2:1·Prefill-only:Cold vs Warm性能对比(DeepSeek-R1,1.6T)
图16 X86后端·EC 4+2:1·Prefill-only:Cold vs Warm性能对比(DeepSeek-R1,1.6T)
在 Prefill-only 场景下,“单副本”与 “EC 纠删码”的 TTFT 加速比和吞吐(TPS)加速比逐场景互有高低、整体持平。这两种存储策略在卸载场景下性能无可辨别差距。
 图17 X86后端·单副本vs EC·Prefill-only:加速比对比
图17 X86后端·单副本vs EC·Prefill-only:加速比对比
在 Prefill-Decode 测试中,以每秒完成请求数(req/s)衡量端到端吞吐,“单副本”与 “EC 纠删码” 的 req/s 加速比同样接近,逐场景方向随机。
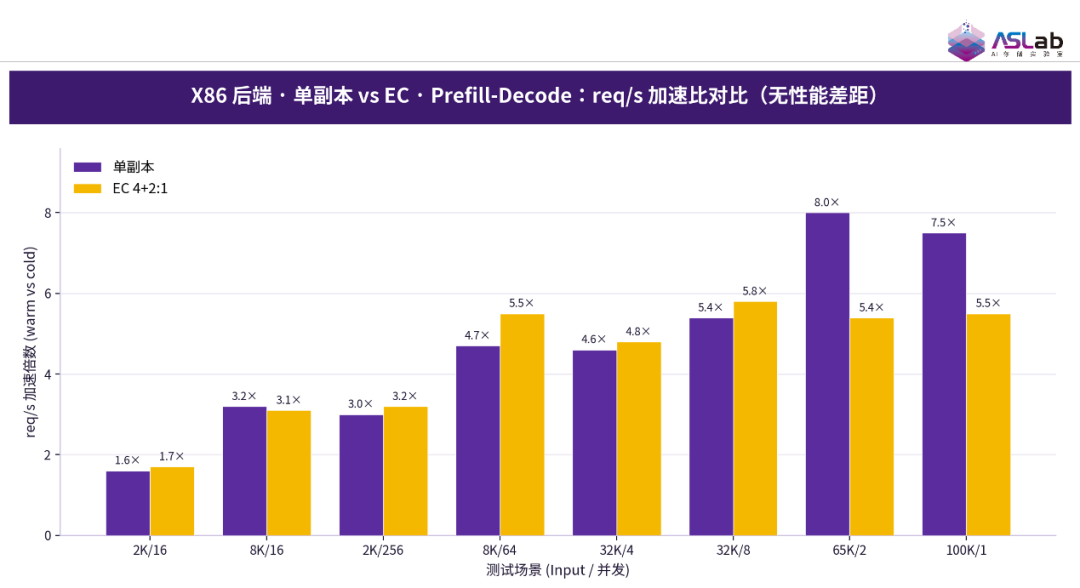 图18 X86后端·单副本vs EC·Prefill-Decode:req/s加速比对比
图18 X86后端·单副本vs EC·Prefill-Decode:req/s加速比对比
NVIDIA Spectrum-X 网络高级特性对于 KV Cache 卸载性能的影响
本次测试基于 Spectrum-X 网络的高级特性,重点评估了 Adaptive Routing 与 Spectrum-X Congestion Control 功能对推理性能的影响。在 Qwen3‑235B 模型、2K 输入长度及 256 高并发的 Prefill‑only 场景下,以关闭 ARCC 为基线,对比了开启 ARCC 后 KV Cache 命中(Warm)路径的性能。结果表明,开启 ARCC 后,吞吐量与请求吞吐均提升约 22.7%,首 Token 延迟(TTFT)改善约 18.7%,充分验证了 Spectrum-X 网络高级特性在提升推理效率方面的积极作用。
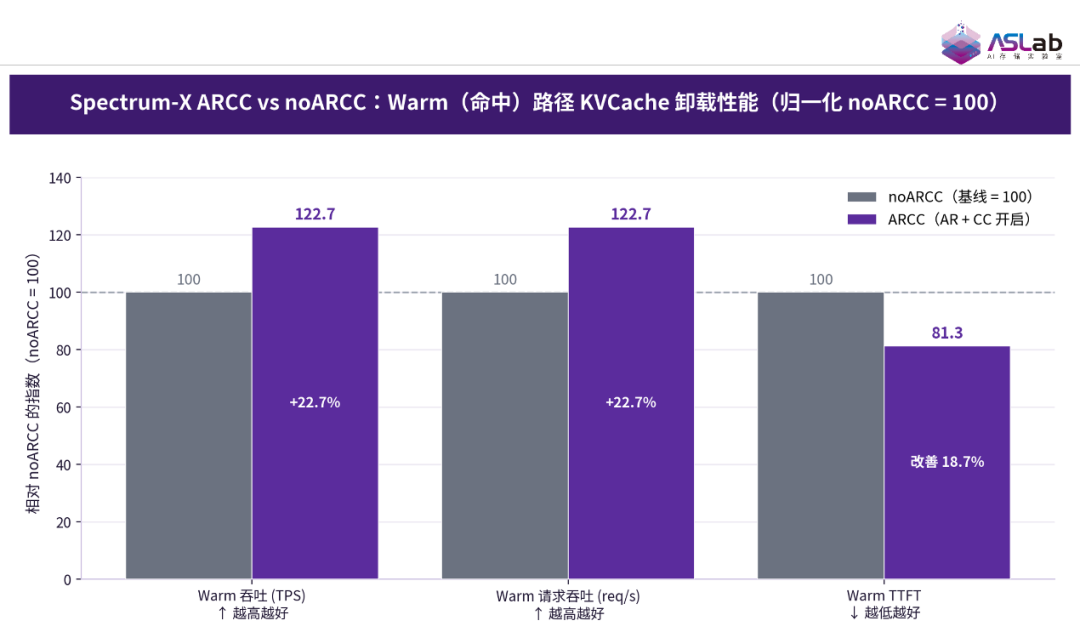 图19 Spectrum-X ARCC vs noARCC: Warm (命中)路 KV Cache卸载性能
图19 Spectrum-X ARCC vs noARCC: Warm (命中)路 KV Cache卸载性能
网络带宽对于推理性能的影响
本次测试验证 GPU 服务器使用 1.6T/800G/400G 存储网络下 KV Cache 卸载性能(Prefill-only 测试)。测试结果表明,1.6T 与 800G 两档存储网络性能基本贴合且维持高位,而 400G 始终垫底。400G 相对 1.6T 的吞吐比值随 Input 增长从 79%单调下滑至 55%。说明请求上下文越长、单请求 KV Cache 越大,400G 单口带宽越成为瓶颈。而 800G 已能满足当前负载、受限于当前 GPU 规格算力制约 4×400G 的边际收益有限。
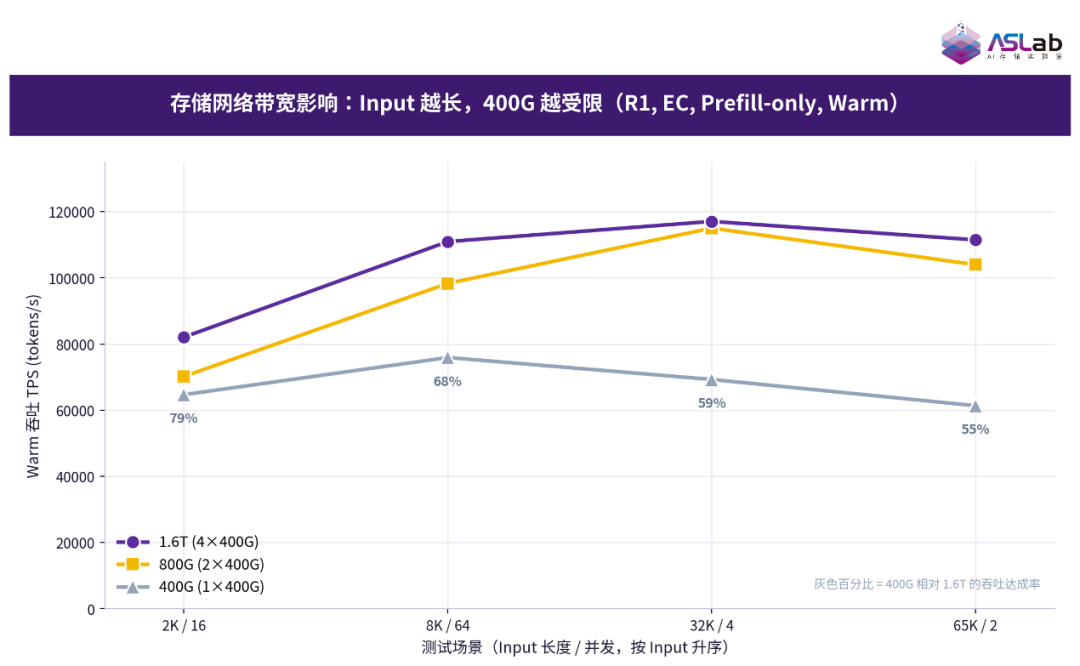 图20 存储网络带宽影响:Input越长,400G越受限(R1,EC,Prefill-only,Warm)
图20 存储网络带宽影响:Input越长,400G越受限(R1,EC,Prefill-only,Warm)
本次测试也验证了 2 台 GPU 服务器使用 800G/400G 计算网络下的 PD 分离测试的性能。在 PD 分离架构下,P 节点和 D 节点间传输 KV Cache 的计算网络从 400G 升级到 800G 后,TTFT 加速比与吞吐加速比逐场景显著提升,800G 普遍约为 400G 的 1.7 倍(TTFT)和 1.5 倍(TPS)。说明对依赖 PD 间 KV Cache 传输的场景,提升计算网络带宽可带来明显的端到端性能收益。
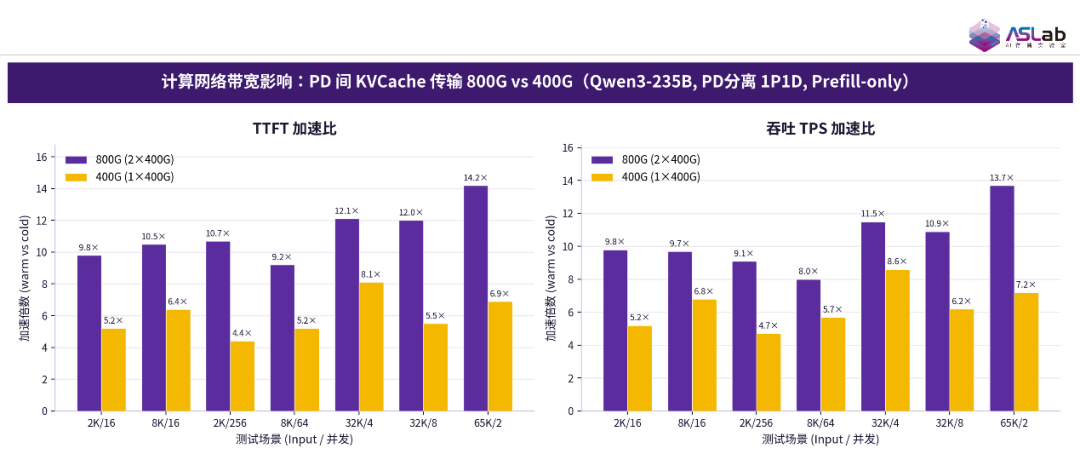 图21 计算网络带宽影响:PD间KV Cache传输800G vs 400G(DeepSeek-V4-Flash, Prefill-only)
图21 计算网络带宽影响:PD间KV Cache传输800G vs 400G(DeepSeek-V4-Flash, Prefill-only)
总结展望:以创新架构推动多元场景落地
本次测试基于 NVIDIA 计算与网络平台,系统覆盖 X86 存储服务器与基于 BlueField-3 DPU 的 JBOF(类似 NVIDIA CMX 架构)两类存储后端,同时验证了“单副本”与“EC 纠删码”两种存储策略,并选取 DeepSeek-R1、Qwen3-235B、DeepSeek-V4(混合注意力)、GLM-5.1(混合注意力)等多款主流大模型作为测试负载,力求全面评估方案在不同硬件形态与模型架构下的适配能力与性能表现。
作为 ODCC AI 存储实验室的重要实践,本次测试不仅验证了 KV Cache 专用存储系统在推理场景下的技术可行性与性能优势,也为 AI 基础设施的标准化建设与产业落地提供了可复用的测试方法论与参考基准。
未来,XSKY 将持续深耕 AI 存储底层技术创新,持续迭代 MeshFusion 系列产品,推动 KV Cache 存储方案的标准化与规模化落地,携手生态伙伴共同加速智算产业的创新与发展。
















